
互联网敏捷研发,离不开高效的代码管理系统。作为研发流程的基础环节,代码管理具备串联需求管理、持续集成、持续交付等上下游研发链路的作用,也承载着企业追求代码质量、鼓励代码复用等工程师文化的建设。腾讯拥有近3万研发人员,产品线漫长、业务种类繁多,不同的团队规模、技术栈和研发模式都对研发协作提出了不同的需求,也导致了代码库规模和研发流程参差不齐。同时编译系统、发布系统等需要检出所有代码,自动化程度越高,对代码库的访问压力就越大。提供安全稳定的代码服务,管理不同规模的代码仓库,支持各种类型的研发流程,是代码管理面临的三大挑战。基于行业状况及自身发展需要,腾讯选择了以Git为基础,在内部孵化了自研的Git系统——工蜂。
首先要解决服务端代码库存储扩容问题,因为单存储节点无法满足TB级增长的存储量,可考虑的有自定义数据分片和通用分布式文件存储两种方案。分布式存储的优点是对应用层屏蔽了底层存储结构,架构相对简单,但对IO密集型的代码托管应用来说,过于依赖分布式文件系统的IO性能,可移植性也不强。相反自定义数据分片可以自由控制分片策略,灵活均衡资源负载,另外在每个分片的底层存储上,也可以结合分布式存储,进一步扩展数据备份。工蜂选择了数据分片的方案,以仓库路径作为路由规则,并在应用层实现跨分片操作。数十万仓库分布在不同集群,可以实现集群动态扩容和集群间无缝迁移。
解决了存储扩容问题后,访问量增加逐步暴露了单机的性能瓶颈,代码库的读取和写入都集中在一台主机上,会导致计算和内存资源吃紧。通过分析来源,大量的读请求来自编译和发布系统,针对这种读多写少的场景,工蜂实现了代码库级一主多从的读写分离模式,写请求分发给主机,读请求会根据当前负载情况均衡分流给从机。主从间的数据同步采用Git原生操作,最大程度保证操作的原子性和数据一致性。同时从机作为实时热备数据,配合异地冷备,建立了完整的代码库数据容灾体系,以保证数据安全性。图1是完整的代码库后端存储架构。
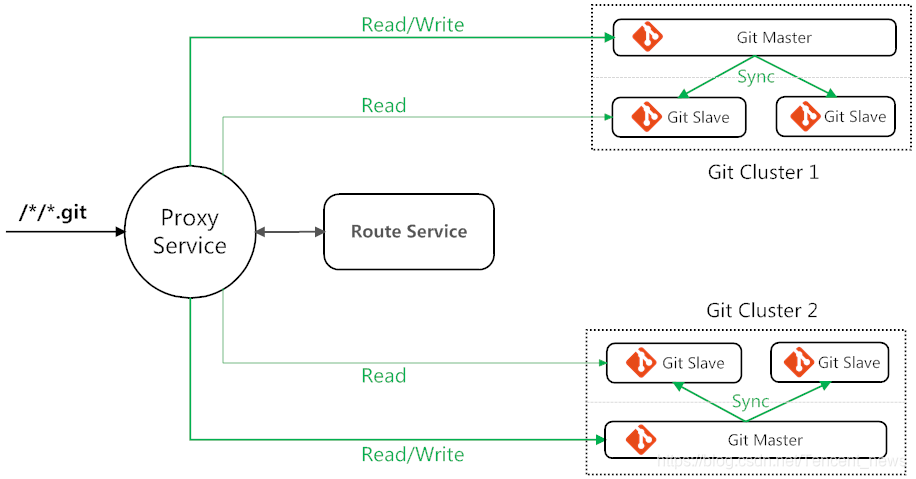 图1 数据分片和读写分离
图1 数据分片和读写分离
如何管理超大库一直是代码管理工具的难题,Git的设计初衷是管理文本类的代码文件,但工程中免不了会有依赖库和资源文件等,特别是腾讯的游戏类业务,包含大量的图片、音视频文件,使得这个问题在腾讯更为凸显。工蜂引入了开源的扩展方案Git LFS,专门托管大型二进制文件。如图2所示,通过把这些文件存储在Git仓库之外,在Git仓库中只保留文件的文本指针,这种方式可以极大减小Git仓库本身的体积,加快克隆仓库的速度。目前工蜂托管的单个大型游戏仓库超过2.5T,单库上限问题得以解决。
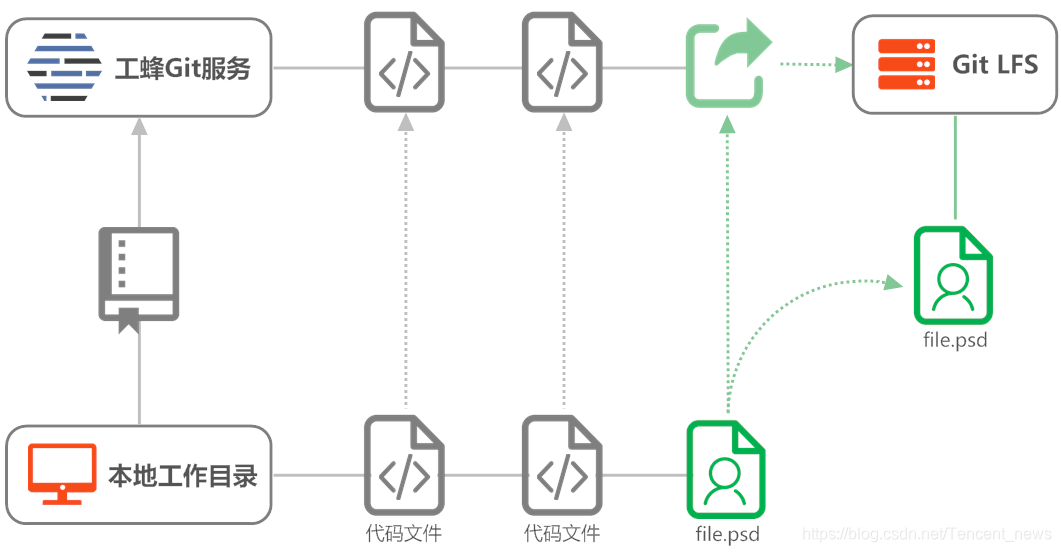 图2 大文件存储
图2 大文件存储
整体架构上,工蜂采用了业界流行的微服务架构。图3中,协议代理服务为HTTP、SSH、LFS三类协议提供独立的访问链路,数据服务封装了数据库访问,路由服务为每个请求寻址后端代码库的数据节点,业务服务根据平台提供的功能拆分,例如代码浏览、代码统计、代码评审、代码搜索等都是独立的微服务。此外,统一的注册中心和配置中心提供服务发现、服务路由、异常熔断和服务配置等全局功能。所有微服务都设计为无状态模式,可以方便的水平扩展。借助容器化部署的能力,能随时调整实例数量以应对高并发场景。
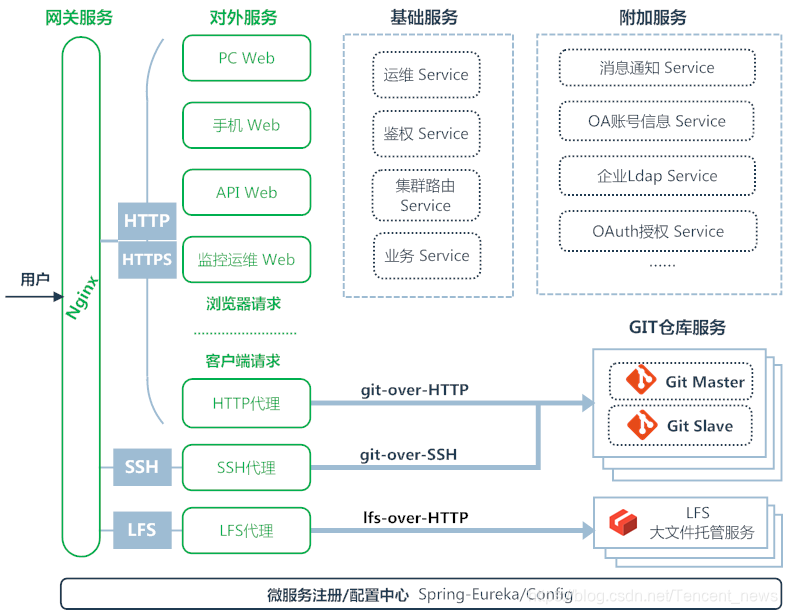 图3 微服务架构
图3 微服务架构
代码工具如果不与上下游研发流程打通,对提升研发效能的作用就非常有限。工蜂的优势之一在于丰富的开放能力,支持第三方系统集成接入。Webhook推送机制,便于第三方订阅代码库提交事件,广泛用于提交代码后自动触发持续集成系统编译构建。Commit Check拦截机制,用于代码合入前自动流水线发起代码规范、缺陷检测、单元测试等代码检查,通过设置质量红线,严控合入代码的质量。工蜂还提供了丰富的符合restful标准的API,完善了私人令牌和OAuth授权机制,给第三方提供了安全有效的标准化接入方式,扩展了工蜂的应用场景。
在腾讯内部,工蜂已在六大事业群全面普及,服务了包括微信、QQ在内的数千条业务线,代码库数量近二十万,日访问量达千万级别,API日均调用数百万次,有效提升了公司的整体研发效能。在公司内部开源协同的战略目标下,工蜂也在潜移默化的改变公司的协作方式,目前工蜂的项目中已有半数以上实现了对内完全开源,用Issue讨论也正成为跨团队协作的有效沟通方式。
今年9月底,“腾讯工蜂——基于Git的研发工程平台”项目在中国计算机学会的评选中脱颖而出,荣获2019年“CCF科学技术奖”。据悉,“CCF科学技术奖”授予对象为在计算机科学、技术或工程领域具有重要发现、发明、原始创新,在相关领域有一定国际影响的优秀成果。本次获奖是对工蜂的极大肯定,未来工蜂将致力于代码复用程度、研发一体化体验、研发过程数据度量等多方面探索,在代码管理领域持续深耕,为公司及行业提供更大的价值。

扫码关注w3ctech微信公众号
共收到0条回复