
前端采用模块化开发,使得开发体验大大增强,摆脱了很多需要人力去做且容易出错的点,使得代码管理更加清晰、规范。主要表现为以下几点:
- 减少命名冲突,消除全局变量
- 一个模块一个文件,组织更清晰
- 依赖自动加载,按需加载
其中文件按需加载,依赖自动管理,使得更多精力去关注模块代码本身,开发时不需要在页面上写一大堆script引用,一个require初始化模块就搞定。不需要每增加一个文件,还要到HTML或者其他地方添加一个script标签或文件声明。
前端模块化规范标准
- CommonJs (Node.js)
- AMD (RequireJS)
- CMD (SeaJS)
注:以下文中出现的AMD及CMD分别范指RequireJS、SeaJS。
CommonJs
CommonJS是服务器模块的规范,Node.js采用了这个规范。根据CommonJS规范,一个单独的文件就是一个模块,每一个模块都是一个单独的作用域,在一个文件定义的变量(还包括函数和类),都是私有的,对其他文件是不可见的。CommonJS规范加载模块是同步的,也就是说,只有加载完成,才能执行后面的操作。
var x = 5;
var addX = function(value) {
return value + x;
};
module.exports.x = x;
module.exports.addX = addX;
AMD (RequireJS)
由于Node.js主要用于服务器编程,模块文件一般都已经存在于本地硬盘,所以加载起来比较快,不用考虑非同步加载的方式,因此CommonJS规范比较适用。但是,如果是浏览器环境,要从服务器端加载模块,这时就必须采用非同步模式,因此浏览器端一般采用AMD规范。如下规范定义及一般写法:
//规范
define(id?, dependencies?, factory);
define.amd = {};
//写法1
define(function(require, exports, module) {
var $ = require('jquery');
//code here
});
//写法2
define(['jquery'], function($) {
//code here
});
//写法3
define(['require', 'jquery'], function(require) {
var $ = require('jquery');
//code here
});
CMD (SeaJS)
CMD规范和AMD类似,都主要运行于浏览器端,写法上看起来也很类似。主要是区别在于模块初始化时机,AMD中只要模块作为依赖时,就会加载并初始化,而CMD中,模块作为依赖且被引用时才会初始化,否则只会加载。如下规范定义及一般写法:
//规范
define(factory);
define.cmd = {};
//写法1
define(function(require, exports, module) {
var $ = require('jquery');
//code here
});
//写法2
define(['jquery'], function(require, exports, module) {
var $ = require('jquery');
//code here
});
兼容AMD、CMD及非模块化
很多时候如果我们引用第三方组件时,并没有采用模块化开发,通常我们自己需要包装一下或通过模块加载器的shim插件支持模块化引用依赖。现在很多第三方库已经默认支持AMD规范的引用,根据以上模块定义规范,开放给第三方使用的组件能兼容不同的规范,如下示例:
(function(root, factory) {
if (typeof define === "function" && (define.amd || define.cmd) {
define(function(require, exports, module) {
return factory(root);
});
} else {
root.dialog = factory(root);
}
})(window, function(root) {
//code here
return dialog;
});
AMD与CMD
这里不对AMD及CMD作详细对比,前面提到一点,最大的差异在于两者的初始化时机不一样,这种差异导致在遇到循环引用时,CMD在某些情况下是可解的,感兴趣的同学可以看下,至于执行效率上,有人专门做过测试,这里不展开说明了。
对于一般使用者来说,RequireJS、SeaJS都是不错的选择,对外调用API上,CMD的API设计更简单,职能更单一,整体实现更轻量也更倾向于CommonJS的规范写法,提倡依赖就近声明。前后端共享模块时,只需要去掉define的包装头部就行了,虽然AMD也支持CommonJS规范的写法,但不是强制的。
同时对于依赖的加载顺序,AMD是不保证按照书写的顺序按序初始化模块的,而这点CMD也更接近CommonJS规范,对于使用者来说require就是同步的。
模块化开发上线部署
- 压缩
- 合并
- 更新版本
不能直接压缩:因为模块加载器在分析模块的依赖时,会先将模块的工厂函数factory.toString(),然后通过正则匹配require局部变量,这样意味着不能直接通过压缩工具进行压缩,若require这个变量被替换,加载器与自动化工具将无法获取模块的依赖。
不能直接合并:我们在开发时,通过是省略模块的ID的,如果多个模块直接合并成一个文件,这样加载器无法区分不同模块了。
所以采用模块化开发上线部署时,压缩前通常通过工具先提取依赖,这样require就可以当做普通变量直接压缩了,同时也不再需要加载器分析提取依赖,对于提升性能也是蛮有好处的。合并前同样也需要借助工具先提取各个模块的ID,然后才能按照合并配置进行合并。整个过程如下:
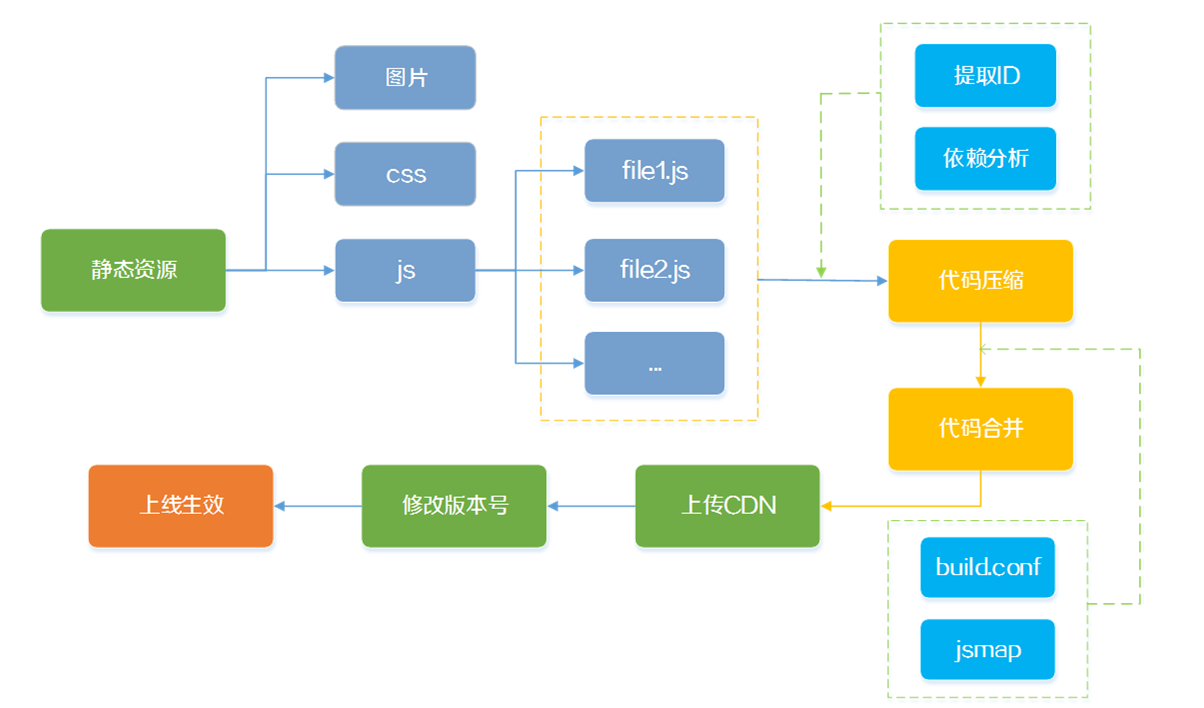
SeaJS和RequireJS官方都提供了构建工具,如SeaJS的spm,RequireJS的r.js,当然也很多grunt和glup插件可使用,区别于普通压缩合并就是要有提取依赖及模块ID的能力。
对比构建工具使用感受,spm的整个上手并不是那么顺畅,配置太复杂。r.js使用相对简单,只需要配置好合并规范的配置文件即可,其它grunt或glup提供的插件相对灵活,可根据自身业务灵活配置。
完成压缩合并后,最后一步就是更新版本号上线了,通常是需要手动更新版本号,或是修改控制版本号的配置参数。这一步基本上还是需要人力手动干预一下。当然如果合并是通过后端的combo服务就不需要了。不管怎么说,通过这些工具的组合使用,整个开发上线流程基本实现自动化了,比较方便。
FIS的集成解决方案
用过fis的同学都知道,采用fis开发,整体过程相当顺畅,对于前端开发、性能、部署各方面的问题基本都考虑到了,内置的小巧mod.js加载器,就是一个特别轻量的模块加载器,不需要做依赖分析,fis强大的编译能力已经提前提取了依赖关系并生成jsmap.json。已经前置依赖了,一个轻量的加载器足足够了,编译的同时自动修改新生成的版本号,整个过程在fis下轻松完成。
- 语言扩展能力 (less, coffee, jade…)
- 前端模板预编译
- xss自动转义 无段手动干预
- 多域名支持,动态切换
- 编译后自动修改版本号 (包括图片的引用)
- 线上本地调试功能 ……
以上纯属个人体会,如有不对,多谢指正!

扫码关注w3ctech微信公众号
-

fis...
回复此楼
共收到1条回复